

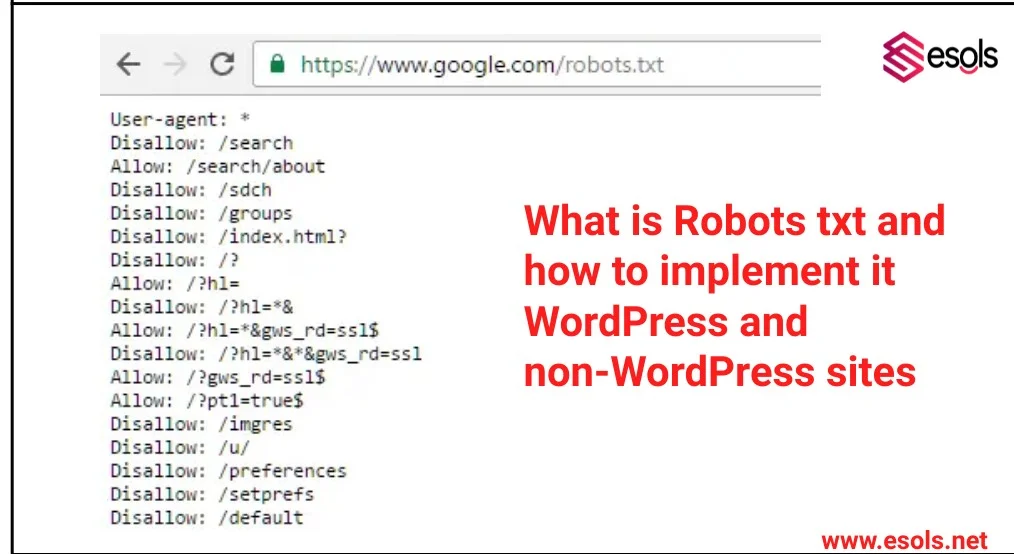
Robots.txt is a text file used to instruct search engine crawlers on how to interact with your website’s pages. It tells search engine bots which pages to crawl and index and which ones to ignore. Implementing robots.txt is crucial for controlling how search engines access and display your site’s content.
Table of contents
Understanding Robots.txt
Robots.txt is a text file that instructs search engine crawlers which pages or sections of a website should or shouldn’t be crawled. It uses directives like “User-agent” to specify the crawler and “Disallow” to indicate pages to exclude. Webmasters can create and edit robots.txt to control how search engines access their site, improving crawl efficiency and SEO. It’s crucial for managing site visibility, preventing indexing of sensitive content, and optimizing search engine rankings.

| Directive | Explanation |
| User-agent | This line specifies the search engine bot or user agent to which the directives apply, such as Googlebot or Bingbot. |
| Disallow | This command tells search engines not to crawl specific pages or directories. For example, Disallow: /wp-admin/ blocks access to the WordPress admin area. |
| Allow | Use this command to override a disallow directive for certain pages or directories. For instance, Allow: /wp-content/uploads/ allows crawling of your WordPress uploads folder. |
| Sitemap | You can include a reference to your XML sitemap in the robots.txt file to help search engines find and crawl your site’s pages more efficiently. Example: Sitemap: https://www.yoursite.com/sitemap.xml |
Implementing Robots.txt on WordPress
Accessing robots.txt:
For WordPress sites, you can create or edit the robots.txt file using a plugin like Yoast SEO. In your WordPress dashboard, go to SEO > Tools > File Editor and add your directives there.
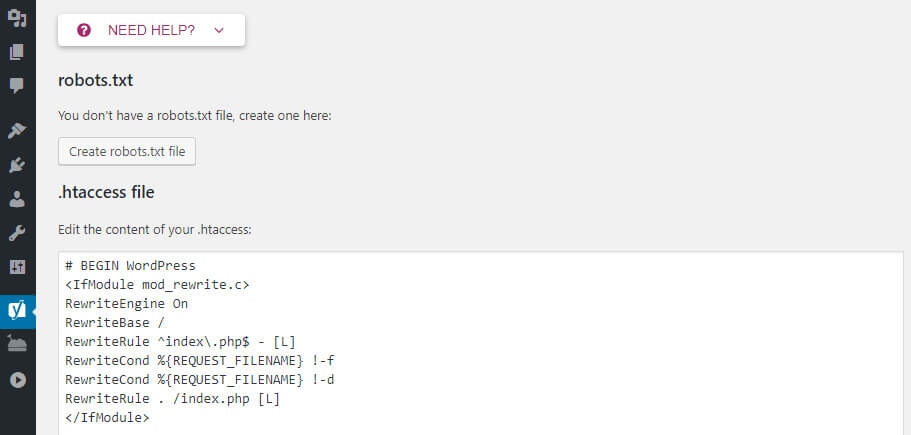
Setting directives:
Use the user-agent lines to target specific bots and the disallow/allow commands to control crawling behavior. Remember to include your sitemap reference if applicable.
Testing:
After saving your changes, use Google’s robots.txt tester tool or a similar tool to check for syntax errors and ensure that the directives are working as intended.
check your robots.txt by Adding Your Domain in Search engine like this : www.esols.net/robots.xt
Implementing Robots.txt on Non-WordPress Sites
Implementing robots.txt on non-WordPress sites involves several steps to ensure proper control over search engine crawlers and the visibility of specific content on your website. Here’s a detailed explanation of each step:

Accessing robots.txt:
- For non-WordPress sites, you need to create a robots.txt file using a text editor like Notepad, Sublime Text, or any code editor of your choice.
- Open the text editor and create a new file. Save the file as “robots.txt” without any file extension.
- Ensure that the robots.txt file is saved in the root directory of your website. The root directory is typically the main folder where your website’s main index file (e.g., index.html, index.php) is located.
Writing directives:
- The robots.txt file uses a specific syntax to instruct search engine crawlers on how to interact with your website’s content.
- You can write directives for different user agents, such as Googlebot, Bingbot, and others, to specify which parts of your site they can crawl and index.
The basic directives include:
- User-agent: Specifies the user agent to which the directives apply. For example, “User-agent: Googlebot” targets Google’s crawler.
- Disallow: Tells the user agent not to crawl specific pages or directories. For example, “Disallow: /private/” blocks access to the “/private/” directory.
- Allow: Allows access to specific pages or directories that are disallowed by default. For example, “Allow: /public/” grants access to the “/public/” directory.
- Sitemap: Optionally, you can include the location of your XML sitemap using the “Sitemap:” directive. For example, “Sitemap: https://www.example.com/sitemap.xml”.
Uploading the file:
- Once you have written the directives in your robots.txt file, save the file.
- Use an FTP (File Transfer Protocol) client like FileZilla or your hosting provider’s file manager to upload the robots.txt file to the root directory of your website.
- Ensure that the file is uploaded correctly and is accessible via the URL: https://www.yourdomain.com/robots.txt
Testing and validation:
- After uploading the robots.txt file, it’s essential to test and validate its effectiveness.
- Use online tools provided by search engines like Google’s robots.txt Tester or Bing’s robots.txt Validator.
- Enter the URL of your robots.txt file (e.g., https://www.yourdomain.com/robots.txt) in the testing tool and check for any syntax errors or misconfigurations.
- Verify that the directives are correctly blocking or allowing access to the intended pages or directories as per your website’s requirements.
By following these steps, you can effectively implement and manage the robots.txt file on your non-WordPress website, controlling how search engines crawl and index your content.
Conclusion
Robots.txt is a powerful tool for controlling how search engines crawl and index your website. Whether you’re using WordPress or a non-WordPress platform, implementing robots.txt correctly can improve your site’s SEO performance by ensuring that search engines focus on the most important pages while ignoring irrelevant or duplicate content. Regularly monitor and update your robots.txt file to align with your SEO strategy and site structure changes.
Readmore : 500 server error: What it mean and how it occurs
FAQ’s
Robots.txt is a text file that instructs search engine crawlers on which pages to crawl and index and which ones to ignore.
You can create a robots.txt file using a text editor like Notepad or through plugins like Yoast SEO for WordPress sites. Specify directives like User-agent, Disallow, Allow, and optionally include a Sitemap.
Yes, you can use the Disallow directive in robots.txt to block search engine bots from accessing certain pages or directories on your website. This is useful for preventing indexing of sensitive or irrelevant content.
You can test your robots.txt file using tools like Google’s robots.txt Tester or Bing’s robots.txt Validator.
